
Những nỗ lực tìm hiểu các model LLMs trong vài tháng trở lại đây nhằm đánh giá và sử dụng các loại LLM đúng với mục tiêu cách mạng hóa công nghệ nhân sự, đặc biệt là trong các nhiệm vụ tuyển dụng như kết hợp CV với JD, và tóm tắt hiệu quả trong việc Management talent. Ở đây, chia sẻ lại một số thông tin có thể hữu ích.
Mục đích của việc này là tìm hiệu quả của model LLM trong việc kết hợp Resume của ứng viên với Job Descriptions. Mẫu thử gồm 10 CVs và 10 JDs, được phân loại theo kinh nghiệm technology và non-technology.
- CVs: 4 entry-level, 3 mid-level và 3 executive-level
- JDs: 4 core tech, 3 non-tech và 3 semi-tech roles
Các models được đánh giá dựa trên điểm bắt nguồn từ thông tin được trích xuất thủ công từ trước cùng một bộ Data. SCORED trên 80% là dấu hiệu của việc đáng tin cậy so với phương pháp trích xuất thủ công.
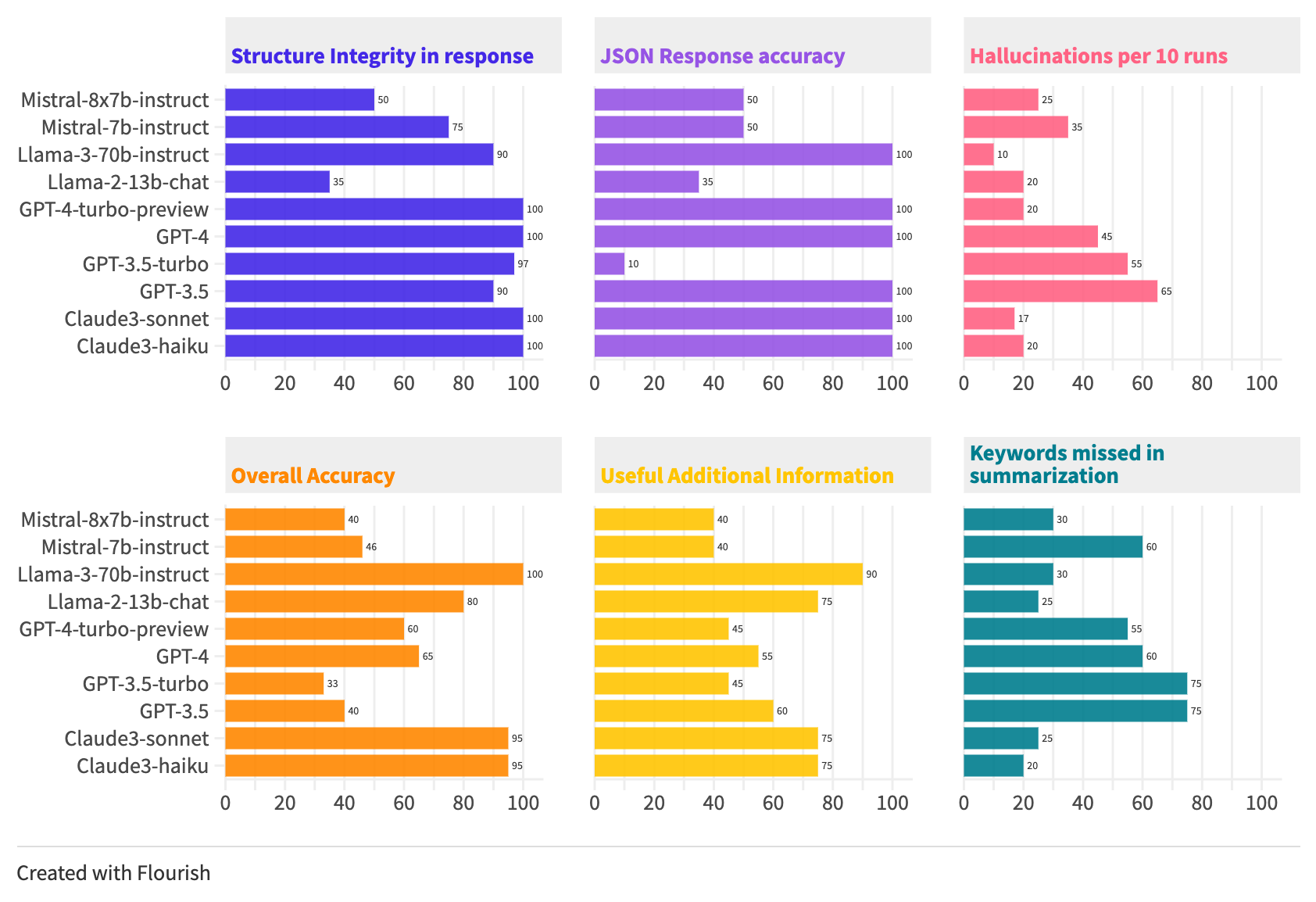
Hiệu suất đáng tin cậy trên 10 models LLM:
- Structure Integrity in response: Độ chính xác trung bình: 83,7%. Mistral và GPT-3.5 đã cho thấy độ chính xác về structure có thể chấp nhận được và một số model khác đạt được 100% như GPT-4 hoặc Claude3.
- JSON Response accuracy: Độ chính xác trung bình: 74,5%. Recommend sử dụng GPT-4 và Llama-3-70b-instruct, cho ra kết quả với khả năng phân tích cú pháp JSON hoàn chỉnh. GPT-4, Llama-3-70b-instruct (100%)
- Hallucinations per 10 runs: Tỷ lệ trung bình: 31,2%, chỉ ra rằng 3-4 trong số 10 phản hồi có thể chứa thông tin không chính xác, bịa đặt và hư cấu. Các tỷ lệ phản hồi khác nhau. Llama-3-70b-instruct (10%)
- Overall Accuracy of match making: Trung bình: 65,4%. Trong đó Llama-3-70b-instruct nổi bật với độ chính xác 100% tuyệt đối, làm cho việc phân tích văn bản có hiệu quả và chính xác. Điều này làm lý tưởng cho các ứng dụng yêu cầu phân tích văn bản chính xác như tuyển dụng, tiếp thị và phân phối nội dung. Có thể nâng cao đáng kể hiệu quả và giảm lỗi.
- Useful Additional Information: Trung bình 60%. Phản hồi này cung cấp hiểu biết theo ngữ cảnh hoặc thông tin bổ sung có giá trị cho các ứng dụng yêu cầu cao như đánh giá sự phù hợp về tính cách và văn hóa trong tuyển dụng thì Llama-3-70b-instruct với điểm số cao nhất là 90%
- Keywords missed in summarization: Các mô hình đã bỏ lỡ trung bình khoảng 45,5% từ khóa quan trọng, cho thấy hiệu suất không cao trong tóm tắt. Trong đó model Claude3-haiku vượt trội hơn các mô hình khác trong việc nắm bắt thông tin chính trong khi tóm tắt CV theo JD, tỉ lệ bỏ lỡ thấp nhất là 20%
Kết quả:
- Llama-3-70b-instruct vượt trội trong việc tạo ra kết quả chính xác với Hallucinations tối thiểu, chứng minh hiệu quả cao để khớp dữ liệu chính xác.
- GPT-4 và GPT-4-turbo-preview cho thấy hiệu suất mạnh mẽ trong việc duy trì cấu trúc và độ chính xác phân tích cú pháp JSON, mặc dù chúng có thể được hưởng lợi từ những cải tiến trong việc giảm Hallucinations.
- Từ những đánh giá trên, các models dưới đây cho thấy hiệu suất vượt trội của chúng trong các chức năng nhân sự chính của việc kết hợp tuyển dụng, so sánh sơ yếu lý lịch và mô tả công việc và kỹ năng tóm tắt: GPT-4, GPT-4-turbo-preview, LLama-3-70b-instruct, Claude3-sonnet, Claude3-haiku.